An Overview of Hardware Acceleration on Embedded Platforms
In 1965, Gordon Moore observed that the number of transistors on integrated circuits doubled every two years. This observation seemed to be true and was dubbed Moore’s law. CPUs were getting denser and with higher clock rates came an exponential increase in performance. But Moore’s law was a long time ago, in fact it was so long ago back when humans haven’t even set foot on the Moon (or on a film set in California depending on who you ask). Today it is often quoted that Moore’s law is dead. Nevertheless, CPUs are still becoming denser, but nowhere near as explosively as before, since they are now pushing against the much more unforgiving laws of physics. Indeed, fabrication processes are nearing the physical limits where quantum effects could disrupt transistor operation.
Fortunately, there are ways to keep satisfying the ever-growing demand for processing power without simply doubling the number of transistors. A big factor is how we organize those transistors. CPUs are generic computational units so they handle most things pretty well, but some applications benefit greatly from specializing the hardware. That is why, for example, GPUs exist. Geometric transformations and matrix operations required when working with graphics are easily parallelized on the uniquely specialized computational unit which is the GPU. This is what we call hardware acceleration.
Edge Computing
Back on embedded platforms, CPUs are much more “economical”. Less memory, lower power requirements and operating frequency, fewer transistors, lower processing power, etc. So it’s not surprising when these systems rely on cloud computing and some remote server to do the heavy number-crunching work for them. But that’s not always the case. By leveraging specialized hardware, embedded systems can take on a variety of tasks in the domains of digital signal processing, machine learning, graphics processing, etc. And in some cases, this is the only feasible approach.
Edge computing is the paradigm that brings computation closer to the source of data. It can be often the case that some application has hard latency requirements. In that case, data must be processed locally. More specifically, we are talking about most ADAS (Advanced Driver Assistance Systems) applications, where data is gathered from local sensors, processed, and a reaction is generated. Any perception task processing radar, lidar, camera or other sensor data, or sensor fusion tasks usually must be done locally. In these cases, specialized hardware enables us to perform all these complex and critical computations on these seemingly underpowered systems with satisfactory latency.
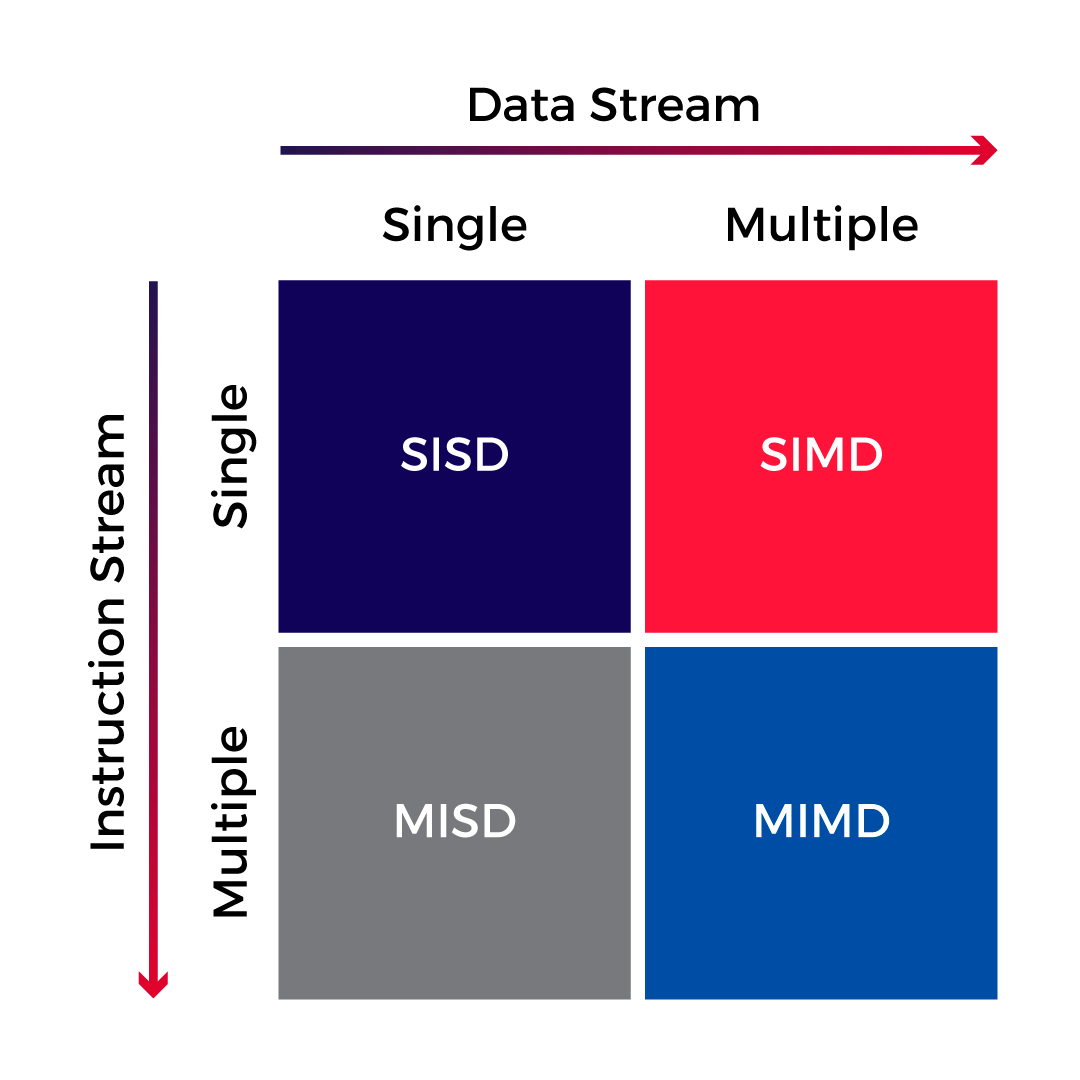
Flynn’s Taxonomy
Hardware Acceleration
So what is hardware acceleration? Simply put, it’s hardware that is designed to optimize the execution of a specific task or group of tasks. Most of the time this boils down to parallelizing the same operation on multiple instances of data. To get a deeper understanding of the concept, we will take a look at Flynn’s classification of computer architectures. Flynn classified computer architectures based on the number of concurrent instruction streams and concurrent data streams. Based on this, he came up with the following four classes:
SISD – Single instruction stream, single data stream
The SISD architecture is capable of performing a single instruction on a single data stream at a time. This architecture can be found in generic single-core CPUs.
SIMD – Single instruction stream, multiple data streams
The SIMD architecture is a popular choice when designing embedded signal processing or parallel processing units, which can be seen in Infineon’s AURIX line of products. Processors with this architecture can apply an instruction to multiple data streams sequentially by pipelining or in parallel.
MISD – Multiple instruction streams, single data stream
This is an obscure architecture that is rarely used. In this variation, multiple instruction streams operate on the same data stream.
MIMD – Multiple instruction streams, multiple data streams
Multiple instructions operating on multiple data streams simultaneously.
SIMD Parallel Processing
As mentioned, the single instruction stream multiple data streams architecture enables pipelining or parallel operation on multiple data streams. A simplified demonstration of the acceleration provided by this architecture can be found in an image processing example. Brightening an image would require increasing the R (red), G (green), and B (blue) components of each pixel in the image. Performing the same instruction, an incrementing operation on all 3 color components can be done in parallel on an SIMD architecture. That is how SIMD works.
More practical uses can be found in modern automotive chips. German semiconductor manufacturer Infineon has included SIMD modules on the AURIX line of products to aid signal processing and matrix operations as part of the SPU (signal processing unit) and PPU (parallel processing unit). Such additions give a lot more processing power to developers to work with, whether they are writing algorithms for radar signal processing, or incorporating machine learning and sensor fusion on the automotive platform.
Arijan Amigh, Development Engineer at NOVELIC
References
[1] https://www.infineon.com/cms/en/product/promopages/new-ppu-simd-vector-dsp/
[2] https://link.springer.com/referenceworkentry/10.1007/978-0-387-09766-4_2
[3] https://www.sciencedirect.com/topics/computer-science/vector-processor
[4] https://www.sciencedirect.com/topics/computer-science/single-instruction-multiple-data